Today we’re going to start with describing the architecture of the Serverless Reservation System which we’re going to build in the upcoming posts.
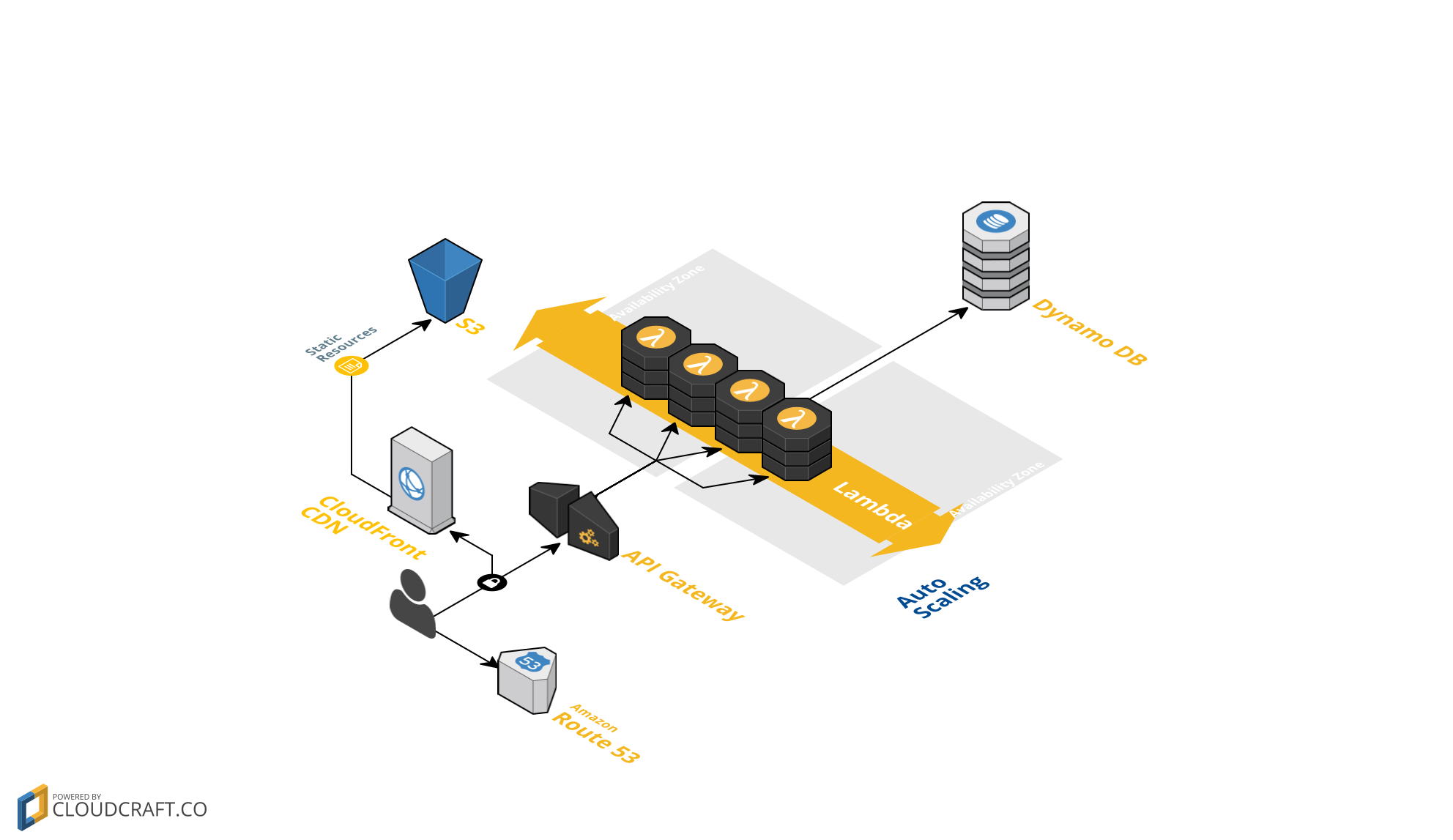
The figure above presents high level view on the system. Let’s describe the main components in more details.
S3
S3 stands for Simple Storage Service. The system will use it to serve static pages. By static I do not mean that it will be pure HTML. We can use any portion of JavaScript in there and build completely functional user interface for our system.
API Gateway
Amazon API Gateway is where we will build secure REST API which clients for our system as sell as our web page will use to perform any actions, such as:
- authenticating and authorizing user
- listing items available for reservation
- booking an item
- listing booked items
- prolonging reservation
API Gateway has one main advantage - it’s very cheap. It is one of the AWS services which is included in Free Tier program. It means that it has a special pricing during the first year after creating an AWS account. During this year you get one million API calls for free each month. If you exceed this nunmber you pay only when the API is really used and at the time of writing this post it costs $3.50 per million API calls plus transfer cost.
An example calculations of costs is listed on Amazon Site. This is the big advantage of servlerless architecture that you don’t need to worry about installing and maintaining any servers, applications or security patches and Amazon will do this all for you. You do not pay 24/7 when your server would have to run, but you only spend money on real usage. When your traffic gets higher you don’t need to worry to add more servers, because the services will scale automatically and in an eye blink (of course you need to properly configure it so that it can scale automatically, but we will get to it in next posts)
Lambda
Lambda is the heart of business logic in our system. Today the architecture of microservices is so popular that I dare to think that everyone already knows what it is about. We can imagine Lambda as a microservices framework in the Cloud which allows to compose the logic of the system from many small building blocks. Lambda allows to write a function in different programming language, deploy it on AWS and configure a trigger when the function will execute. There can be various triggers like:
- when a new file is created/updated/deleted in S3 bucket
- scheduled events
- API Gateway
For the complete list of possible triggers you can check AWS documentation here. For our purpose we are going to use API Gateway triggers.
Dynamo DB
As stated on Amazon site:
Amazon Dynamo DB is a fast and flexible NoSQL database service for all applications that need consistent, single-digit millisecond latency at any scale.
But why Dynamo DB?
There are other storage mechanisms available on AWS. E.g. why not to use relational database in RDS?
Dynamo DB scales better in case when your application needs to read/write huge amounts of data per second. In traditional RDS approach scaling is possible as well e.g. through adding additional database replicas and distributing traffic among them, but at some point you can reach the limit.1
It may sound obvious to use Dynamo DB as it is so great but hold on.
In reality, if you start a small application like this one and you’re used to SQL world like me, I would recommend you start with relational database. Later when your application reaches a limit when relational database will just clutter you may think of moving to NoSQL. In the system which we will build here I will use DynamoDB mostly for educational purpose. I want to get away from comfort zone and fight my own prejudice against it, because in the past I tried to use it already and went very discouraged. Probably that was because of lack of knowledge on how to use it properly. Recently I’ve noticed that there is even downloadable version of DynamoDB which can be installed locally for development purpose. This sounds very interesting. Let’s give it a try.
The end-to-end data flow in the system is very simple and can be pointed out as such:
- The user performs an action on the page or if we built a mobile application that would use the API Gateway directly, then the user could click a button in the mobile app, e.g. to list items which are not yet booked.
- The client application (mobile or web page) invokes API Gateway HTTP request
- API Gateway triggers Lambda function
- Lambda function executes any business logic, e.g. it may query database for available items and returns result to API Gateway
- API Gateway returns result to the client application
- The client application presents the result to the user.
In the next posts we will be developing each part of the system one by one.
Stay tuned and subscribe to my newsletter and I will let you know when new article appears.
References
comments powered by Disqus