This is a continuation of the Serverless Reservation application started in previous posts. In this blog post we’re going to add persistence using DynamoDB.
In the previous post we have secured the API with key. For development purpose it will be easier to comment out these changes. Otherwise we need to add Usage Plans manually everytime we remove the application and deploy it again. You can find source code for this post at Github, it as API key configuration commented out.
First of all we need to define a table in serverless.yml configuration file.
It will look like this:
resources:
Resources:
ItemsDynamoDbTable:
Type: AWS::DynamoDB::Table
DeletionPolicy: Retain
Properties:
AttributeDefinitions:
-
AttributeName: id
AttributeType: S
KeySchema:
-
AttributeName: id
KeyType: HASH
ProvisionedThroughput:
ReadCapacityUnits: 1
WriteCapacityUnits: 1
TableName: 'Items'
DeletionPolicy: Retain means that even if we remove the CloudFormation stack the table with data will still remain.
id of type String (AttributeType: S) is a primary key of the table.
ProvisionedThroughput means how many resources AWS should reserve for reads and writes to the table to guarantee low-latency performance (see the definition)
We do not expect many reads and writes at the moment so setting 1 read and write per second should be enough.
To allow our application to access DynamoDB we need to add additional permission on AWS.
In provider configuration in serverless.yml we will add iamRoleStatements attribute which generates a new policy and all the actions that are defined in this attribute affect all functions in our application.
After the change it will look as follows:
provider:
name: aws
runtime: nodejs4.3
stage: dev
profile: dev_profile
iamRoleStatements:
- Effect: Allow
Action:
- dynamodb: DescribeTable
- dynamodb: Query
- dynamodb: Scan
- dynamodb: GetItem
- dynamodb: PutItem
- dynamodb: UpdateItem
- dynamodb: DeleteItem
Resource: "arn:aws:dynamodb:us-east-1:*:*"
This will allow lambda function to do CRUD and access table description information for all DynamoDB tables in us-east-1 region. We could restrict it to specific table and function, but let’s keep it simple for now.
Now we can add some code to insert items into DynamoDB.
We will update existing src/services/item.js function createItem.
Instead of just returning item passed in the request we’re going to generate an ID key and insert it into DynamoDB using aws-js node library:
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
const uuid = require('uuid');
const itemsTable = 'Items';
...
return new Promise(function(resolve, reject) {
const currentTime = new Date().getTime();
item.id = uuid.v1();
item.createdAt = currentTime;
item.updatedAt = currentTime;
var params = {
TableName: itemsTable,
Item: item
};
dynamoDb.put(params, function(err, data) {
if (err) return reject(err);
return resolve(item);
});
});
Before we can run it we have to add missing dependencies (aws-sdk and uuid) to package.json using command:
npm install --save aws-sdk uuid
A couple of observations so far:
- Our DynamoDB table has deletion policy
DeletionPolicy: Retainand when we remove CloudFormation stack usingsls removecommand then the table remains. If we try to create again the stack it will fail with message that the table already exists. For development we may want to replace it withDeletionPolicy: Delete. - Having custom GraphQL Date type defined in previous blog posts is causing difficulties when saving and retrieving from DynamoDB.
The custom Date type is receiving milliseconds from client and converting to Date object in JavaScript.
- DynamoDB can save timestamp as string (as stated in the doc), but then when we query these fields we need to convert it back to Date format and GraphQL custom type need to convert it again to milliseconds before it is sent to client.
- DynamoDB can save timestamp as int, but since GraphQL custom type has converted value sent from client to Date object, then we have to convert it back to int before saving in database.
Having the above into account it sounds more reasonable to have timestamps as int everywhere in the domain objects and change custom GraphQL type to not do any conversion to Date. Then we will not need any conversions before storing and after querying from database.
const Date = new graphql.GraphQLScalarType({
name: 'Date',
description: 'Date custom scalar type',
parseValue(value) {
return value; // value from the client
},
serialize(value) {
return value; // value sent to the client
},
parseLiteral(ast) {
if (ast.kind === graphql.Kind.INT) {
return parseInt(ast.value, 10); // ast value is always in string format
}
return null;
},
});
Now, let’s deploy and test creating new items.
sls deploy
This outputs URL to the endpoint e.g.:
service: serverless-reservation
stage: dev
region: us-east-1
api keys:
None
endpoints:
POST - https://ixjc3gfd7b.execute-api.us-east-1.amazonaws.com/dev/graphql
functions:
graphQl: serverless-reservation-dev-graphQl
We can insert new Item with command:
curl -X POST -H "Content-Type: application/json" \
-d 'mutation ExampleMutation {createItem(id: "1", name: "demo item", description: "demo description") {name, createdAt}}' \
https://ixjc3gfd7b.execute-api.us-east-1.amazonaws.com/dev/graphql
At the moment we have not yet implemented getting Items from DynamoDB so we can quickly login to AWS console, navigate to DynamoDB and check there if the item was inserted.
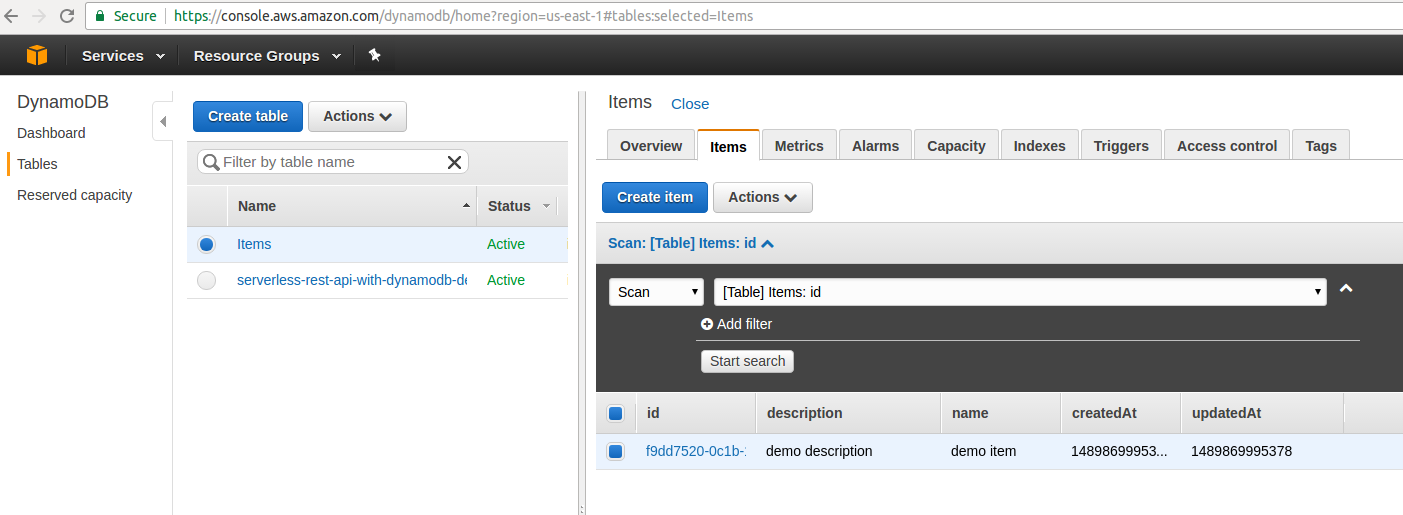
Let’s add code to query items from DynamoDB by name - we will update existing src/services/item.js function findByName(name).
...
return new Promise(function (resolve, reject) {
var params = {
TableName : itemsTable,
ProjectionExpression:"id, #name, description, createdAt, updatedAt",
FilterExpression: "begins_with (#name, :name_substr) ",
ExpressionAttributeNames:{
"#name": "name"
},
ExpressionAttributeValues: {
":name_substr":name
}
};
dynamoDb.scan(params, function(err, data) {
if (err) return reject(err);
return resolve(data);
});
})
...
We use scan method to get data from DynamoDB. This operates on full table content and is inefficient when there are many records.
It would be better to use query method but then we have to add index on the attribute used in query criteria. We will keep this for next blog posts.
References
- serverless youtube course
- Serverless User Guide
- AWS DynamoDB Table Resource Doc
- AWS SynamoDB Query and Scan Doc
- Serverless Todo App