
In my previous post I described how AWS Lambda deployments written in Java could be slimmed down by adding a layer with dependencies.
The current post started with a hypothesis that there is a difference in invocation time of Lambda running with and without layers. I assumed on the beginning that Lambda would need some additional initialisation of Layer when it starts up.
Here is how I measured it:
- I took my existing project and added 4 configurations to measure Lambda execution time:
- cold lambda with layer
- cold lambda without layer
- hot lambda with layer
- hot lambda without layer
- I added config in 4 separate branches there. You can replicate the testing environment by following the instructions in this repo.
Each project will deploy 2 Lambda functions:
- a cron function (A) scheduled to trigger another function (B) on time interval in which I measure execution time of another function and store it in DynamoDB.
InvokeRequest request = new InvokeRequest()
.withFunctionName(FUNCTION_NAME)
.withInvocationType(InvocationType.Event)
.withPayload(payload);
long start = System.currentTimeMillis();
lambdaClient.invoke(request);
long delta = System.currentTimeMillis() - start;
persistData(new StatsRecord(System.currentTimeMillis(), delta));
- a lambda (B) which will do nothing except printing a log message:
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import org.apache.log4j.Logger;
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestStreamHandler;
public class ApiGatewayHandler implements RequestStreamHandler {
private static final Logger LOG = Logger.getLogger(ApiGatewayHandler.class);
@Override
public void handleRequest(InputStream inputStream, OutputStream outputStream, Context context) throws IOException {
LOG.info("Invoked function");
}
}
All Lambda functions are deployed in the same AWS region to minimise network latency.
I assumed 2h as a sufficient time interval for triggering cold startup of Lambda function.
Below are the results I obtained.
Hot Lambda with and without layer
Values gathered in time look as follows:
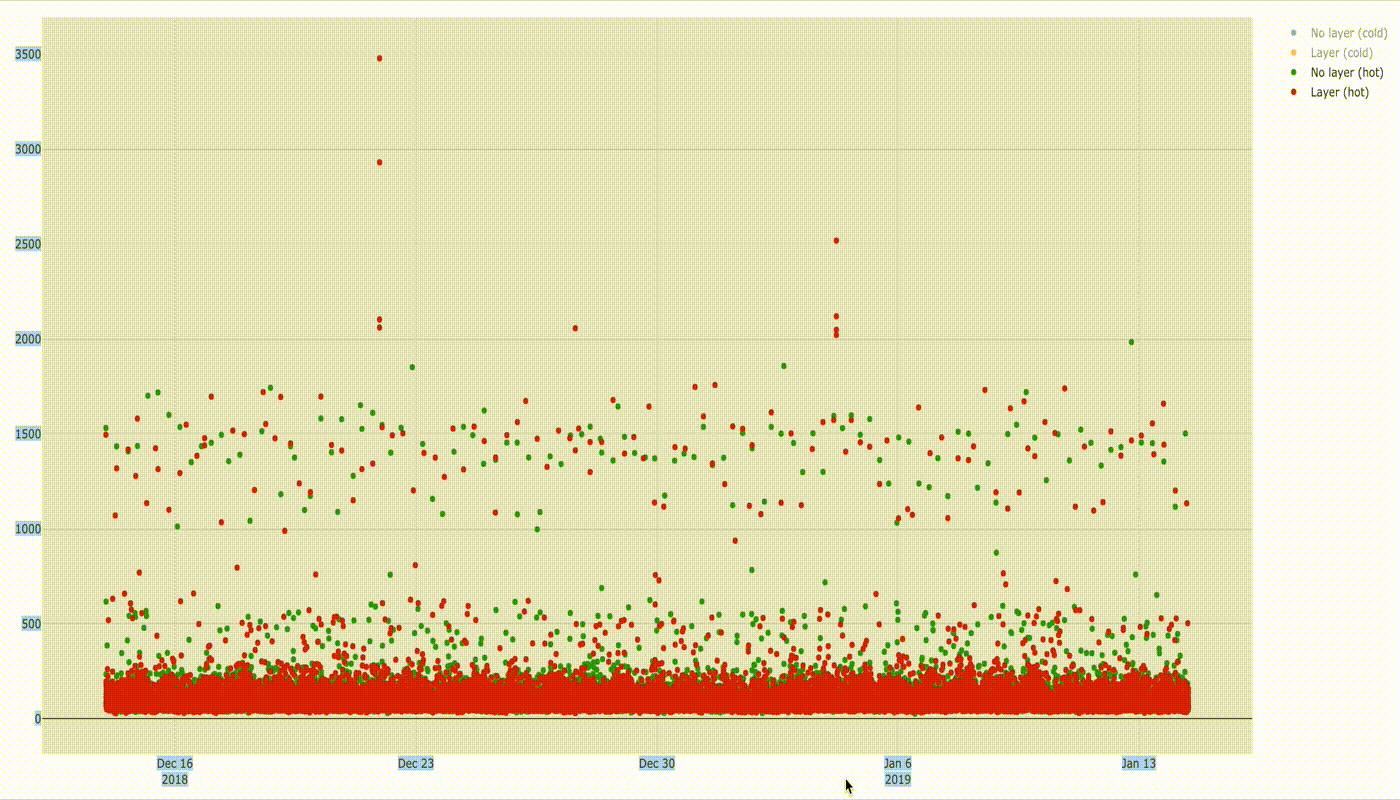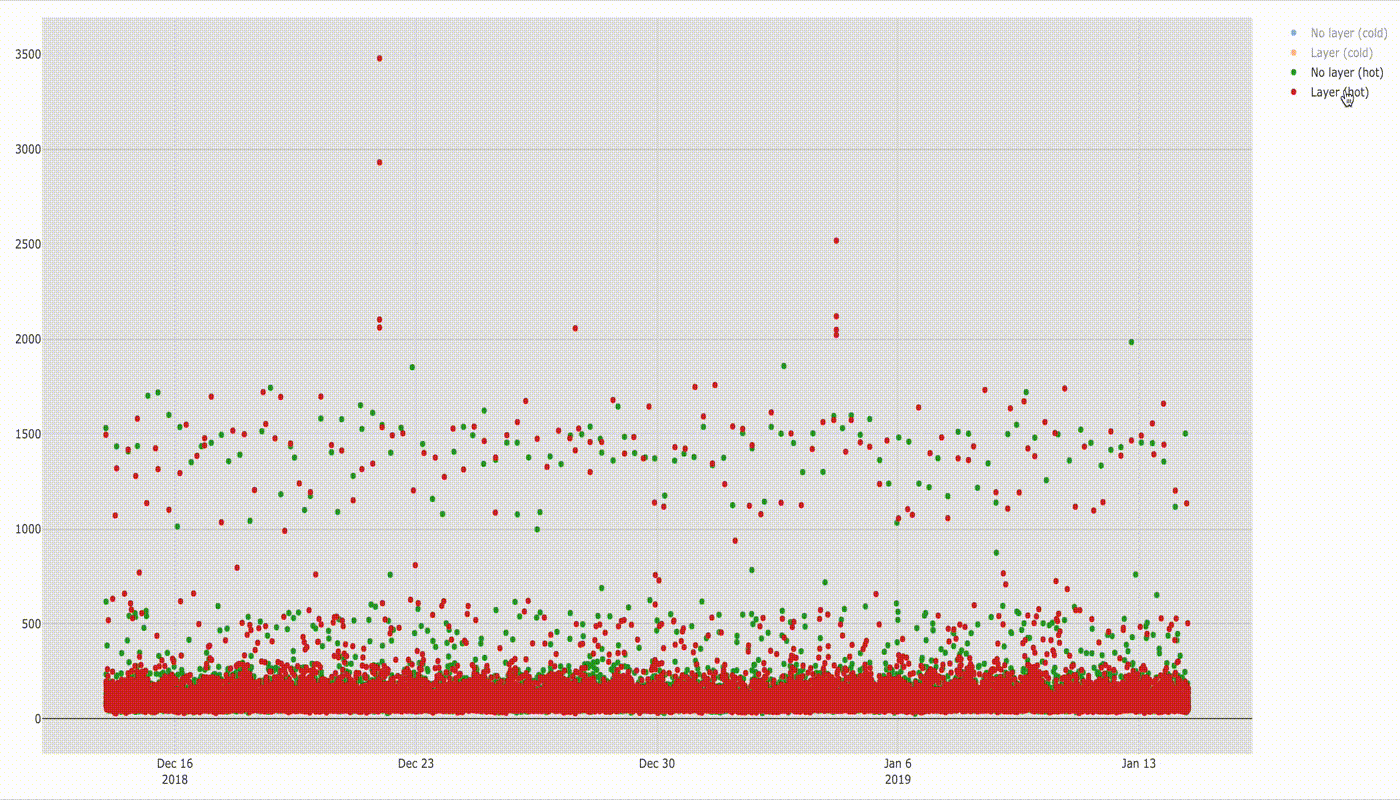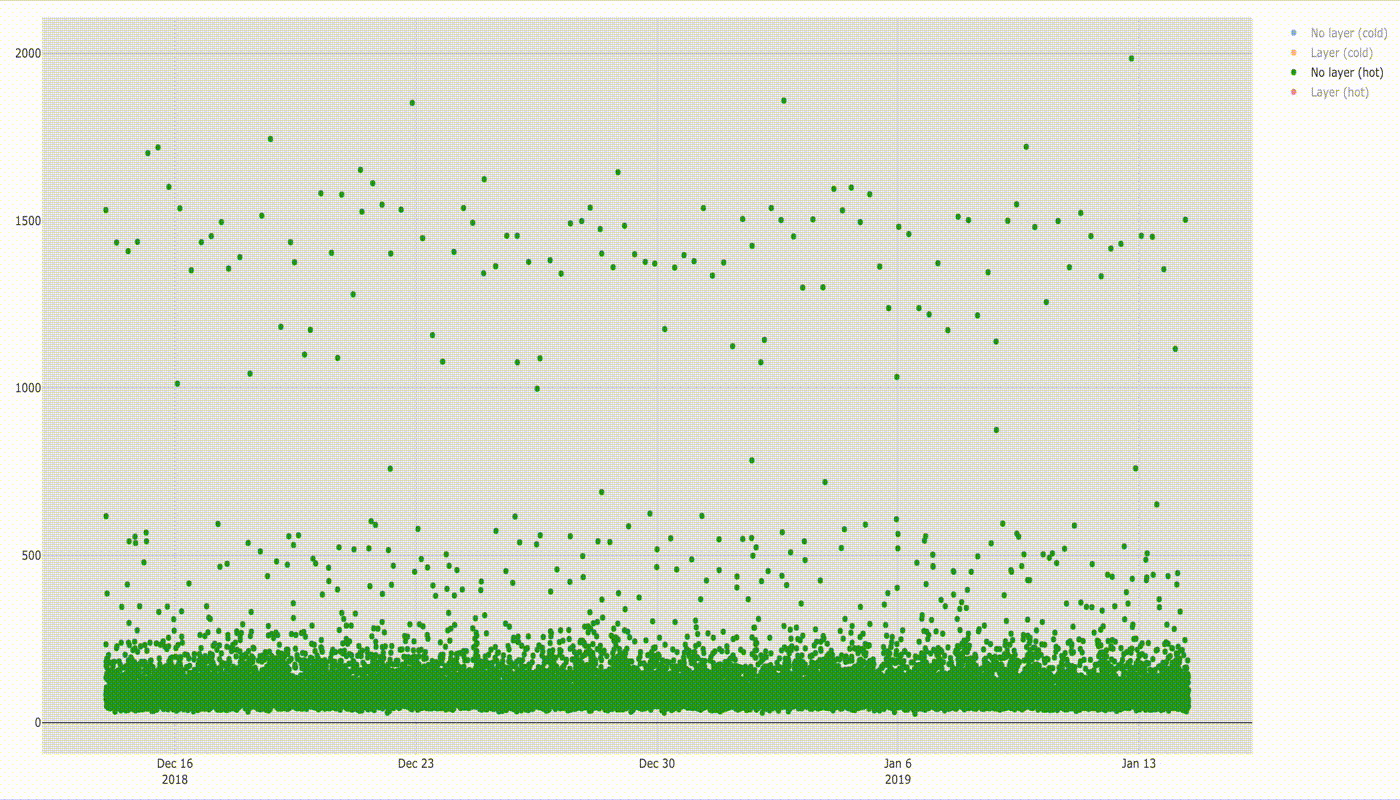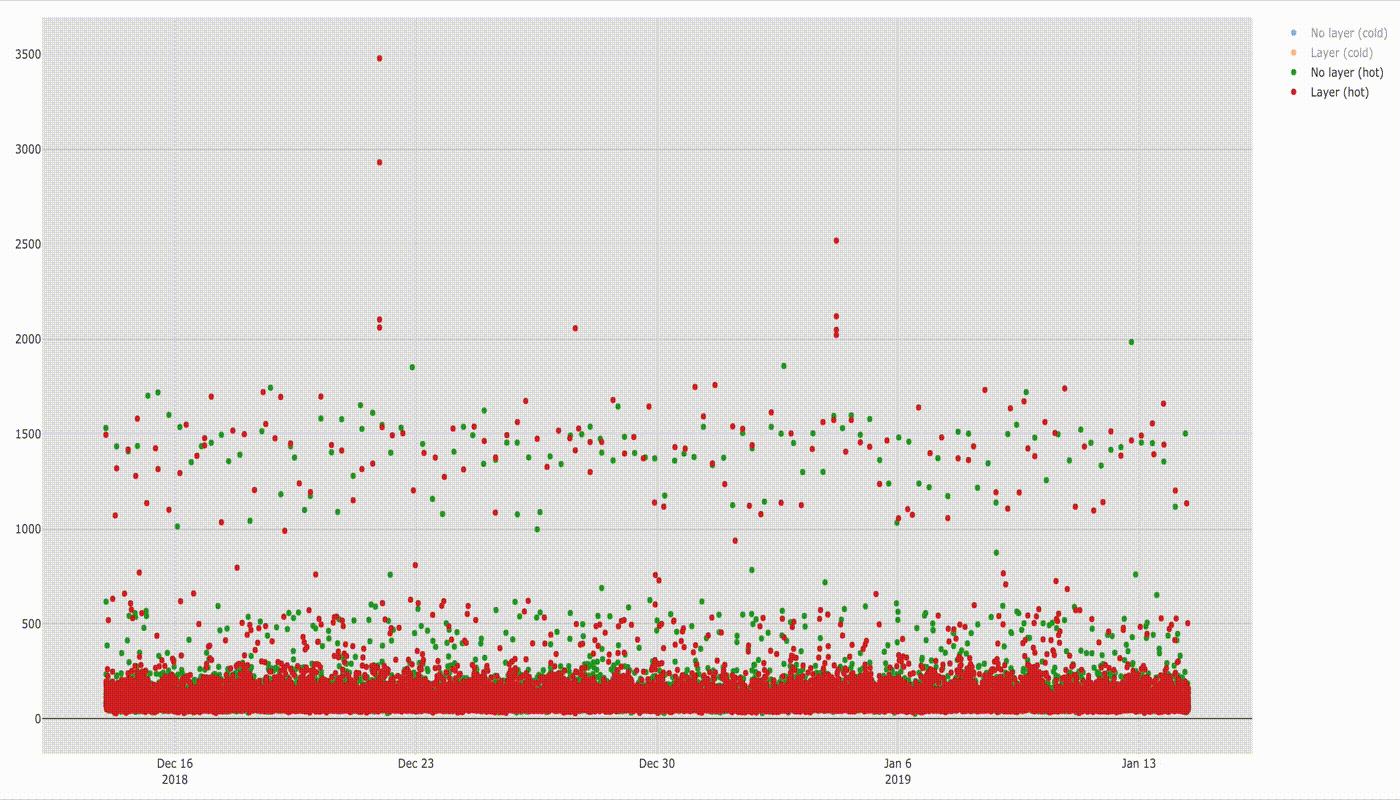
If you discount a few dots above 2 seconds there is not much difference in execution time, but it will be visible better in the box plot below.
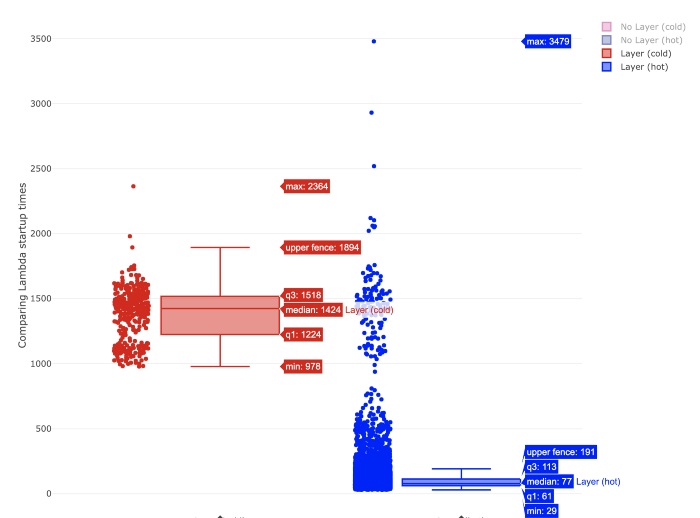
Box plot can tell more about probabilistic distribution of the values. A few introductory words about how to read the diagram for our purpose. Simply, look at the rectangle top and bottom edges (q1 and q2). Specifically, q1 and q2 are respectively lower and upper quantile, which are values dividing the range of probabilistic distribution into intervals of equal probability. The more narrow the rectangular is the more likely is a probability to have execution times from predictable narrow range of values, e.g. in the charts below for hot Lambdas the execution time is more predictable than for cold Lambdas.
Below is the comparison of execution times on box plot.
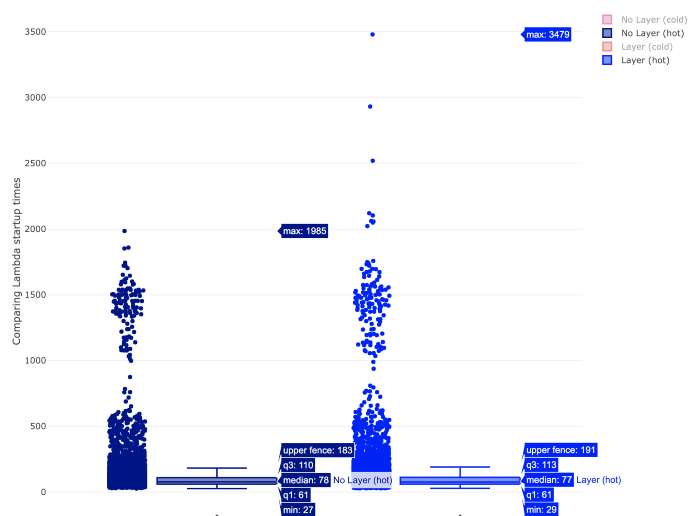
In the above figure we can see comparison of hot Lambda execution times with and without a layer.
Median of execution time for both configurations is similar (78 ms without layer vs 77 ms with layer). Based on the shape of two figures we can see clearly that the distribution of samples is similar. You can also see that there is still a group of values in range ~ 1–2s which stands out from the majority of results. If you compare it with the box chart for cold lambda below you would see that these values match with startup times of cold lambda. I cannot find exact explanation of why it happens but the guess would be that even for hot function sometimes the lambda runtime container is swapped with a new one which needs to initialise the same way when cold lambda is invoked.
Cold Lambda with and without layer
There is also not much difference when running cold lambda function with and without layers.
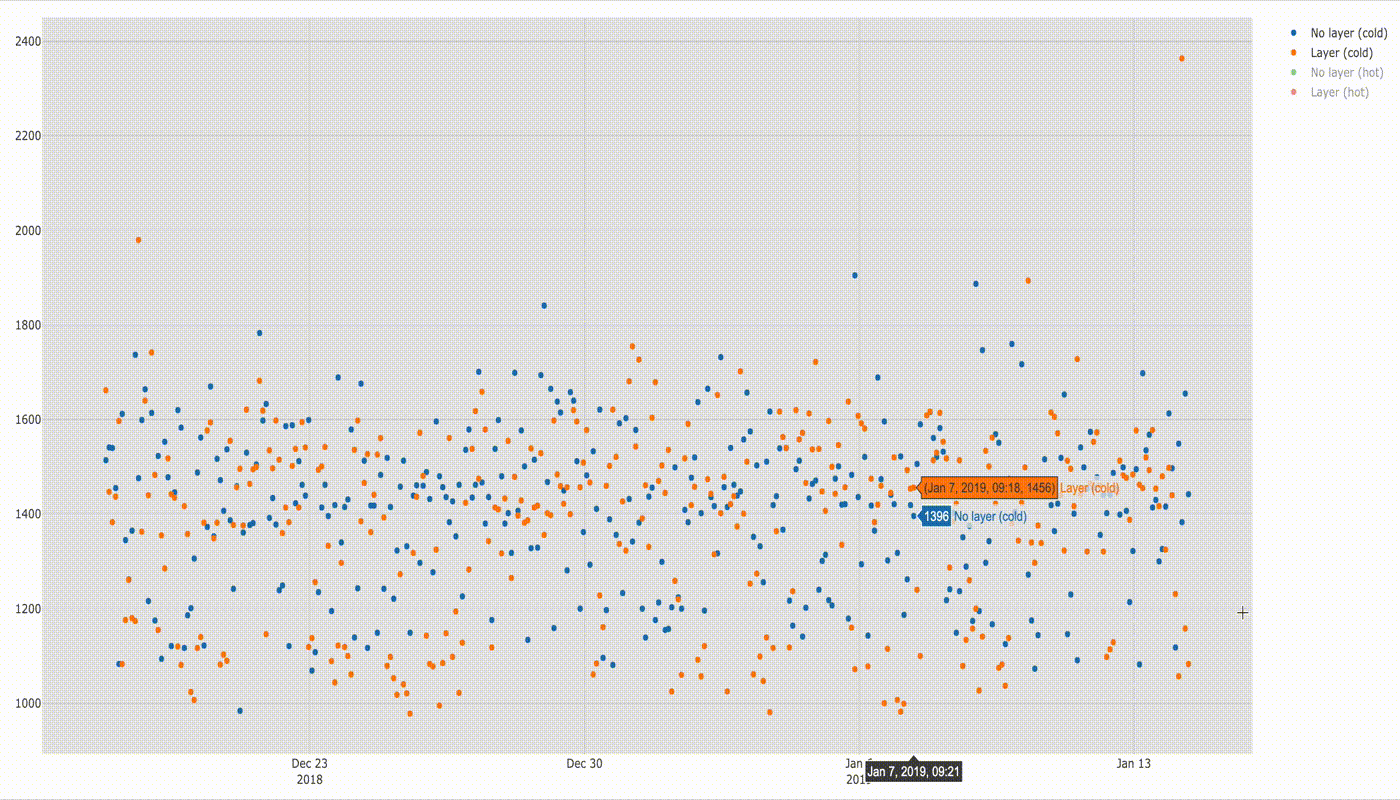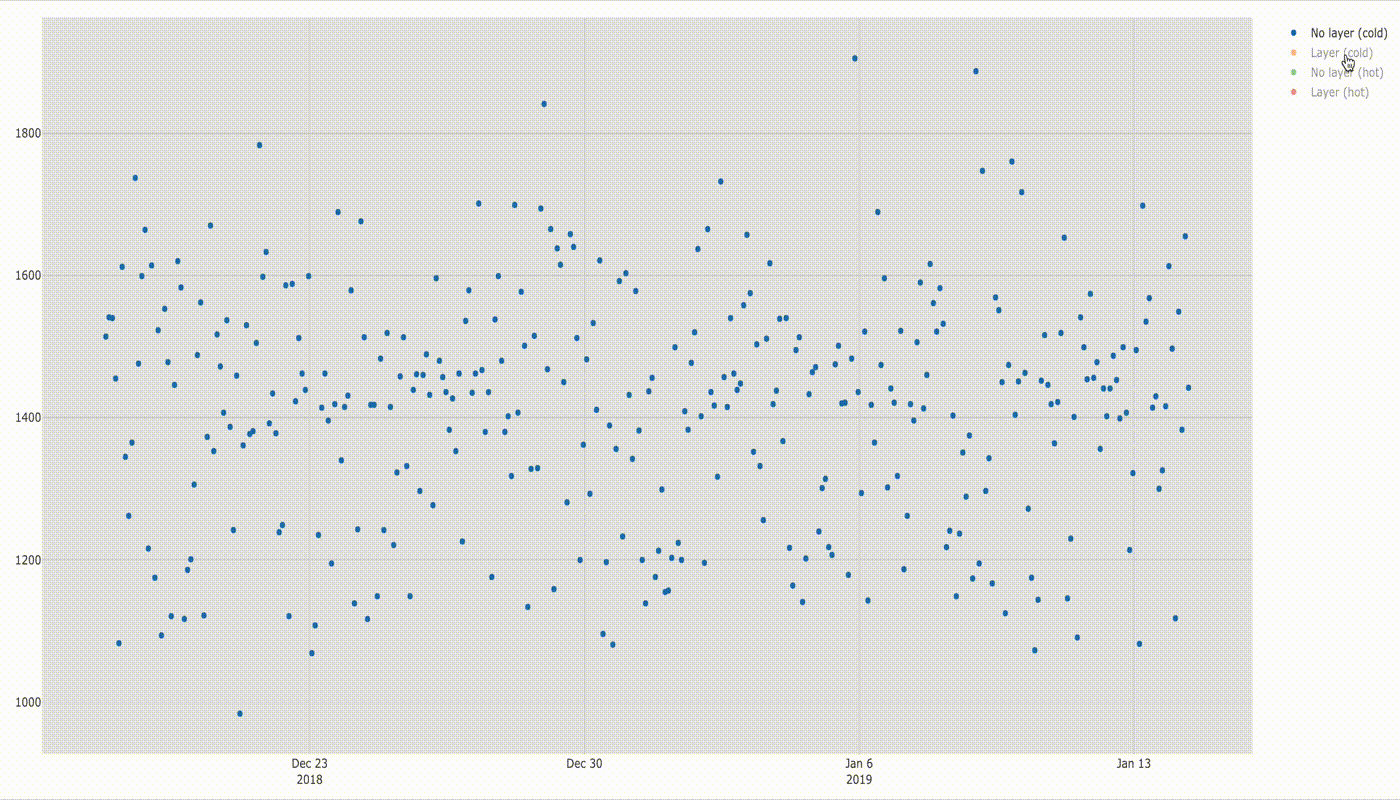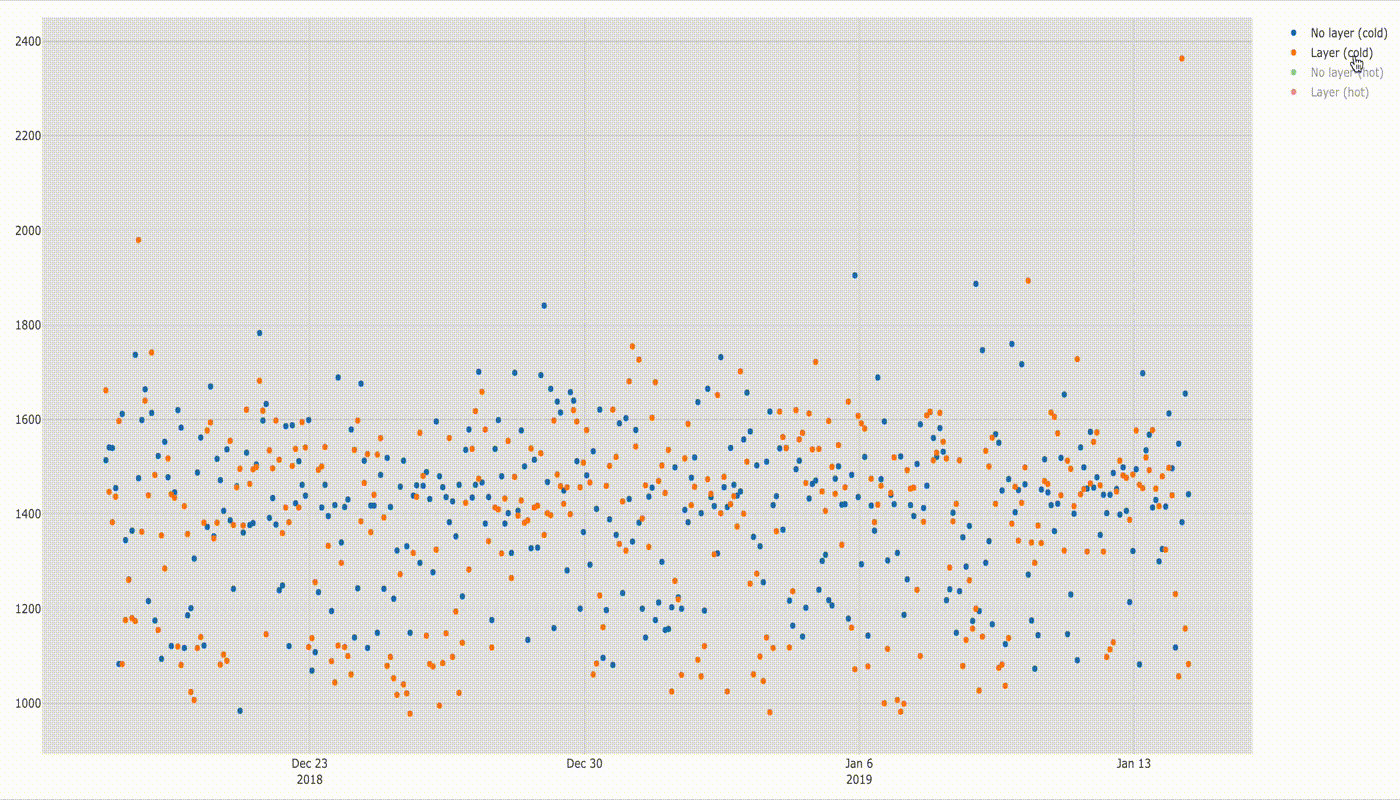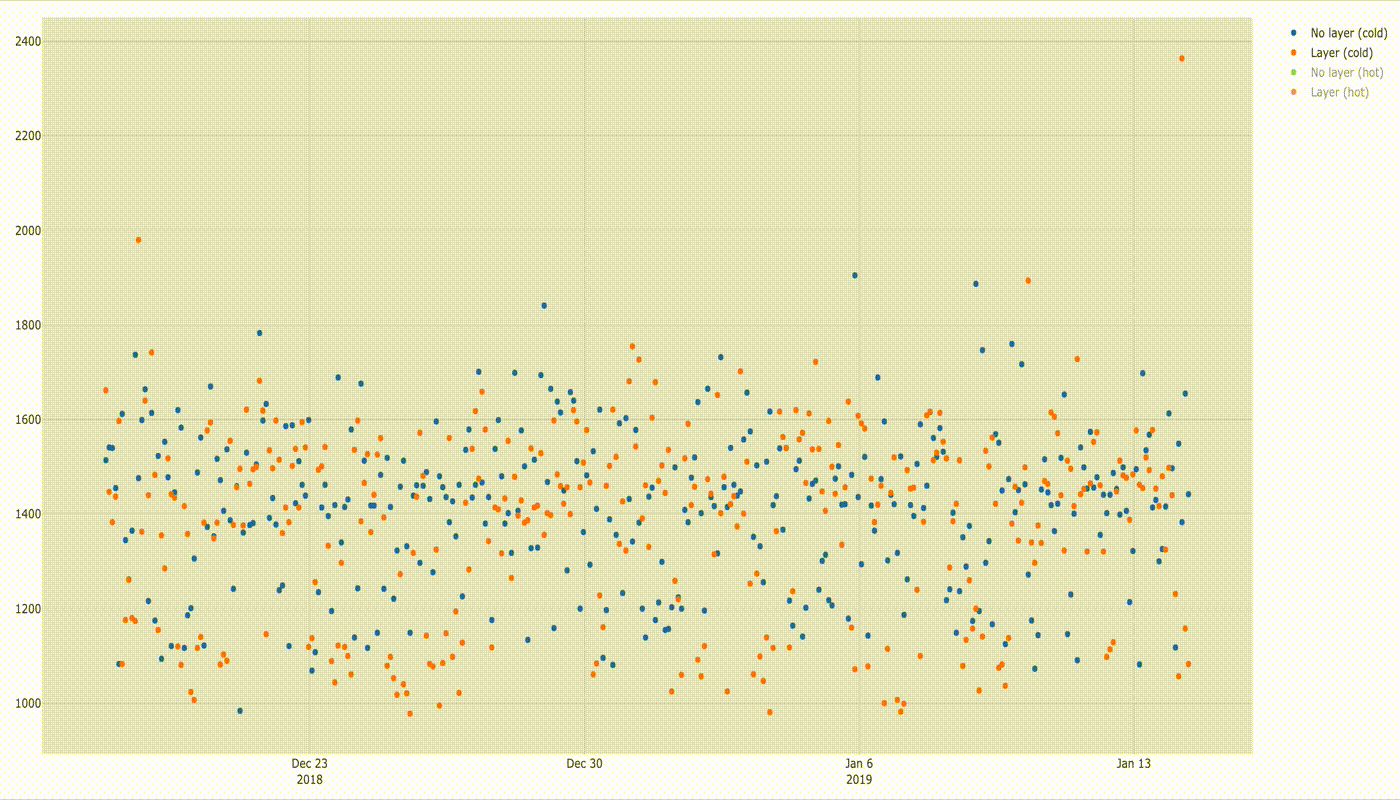
Below is a comparison of execution times.
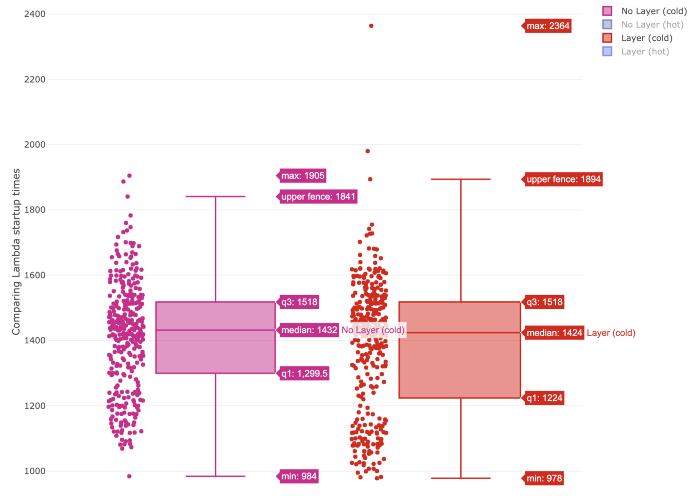
For both cases the median of startup times is similar (1432 ms without layer and 1424 ms with layer). In this case lambda function with layer started quicker more often than without layer (see the bottom of the square — q1 value for both).
Lambda cold and hot without layer
Timeline chart is as follows.
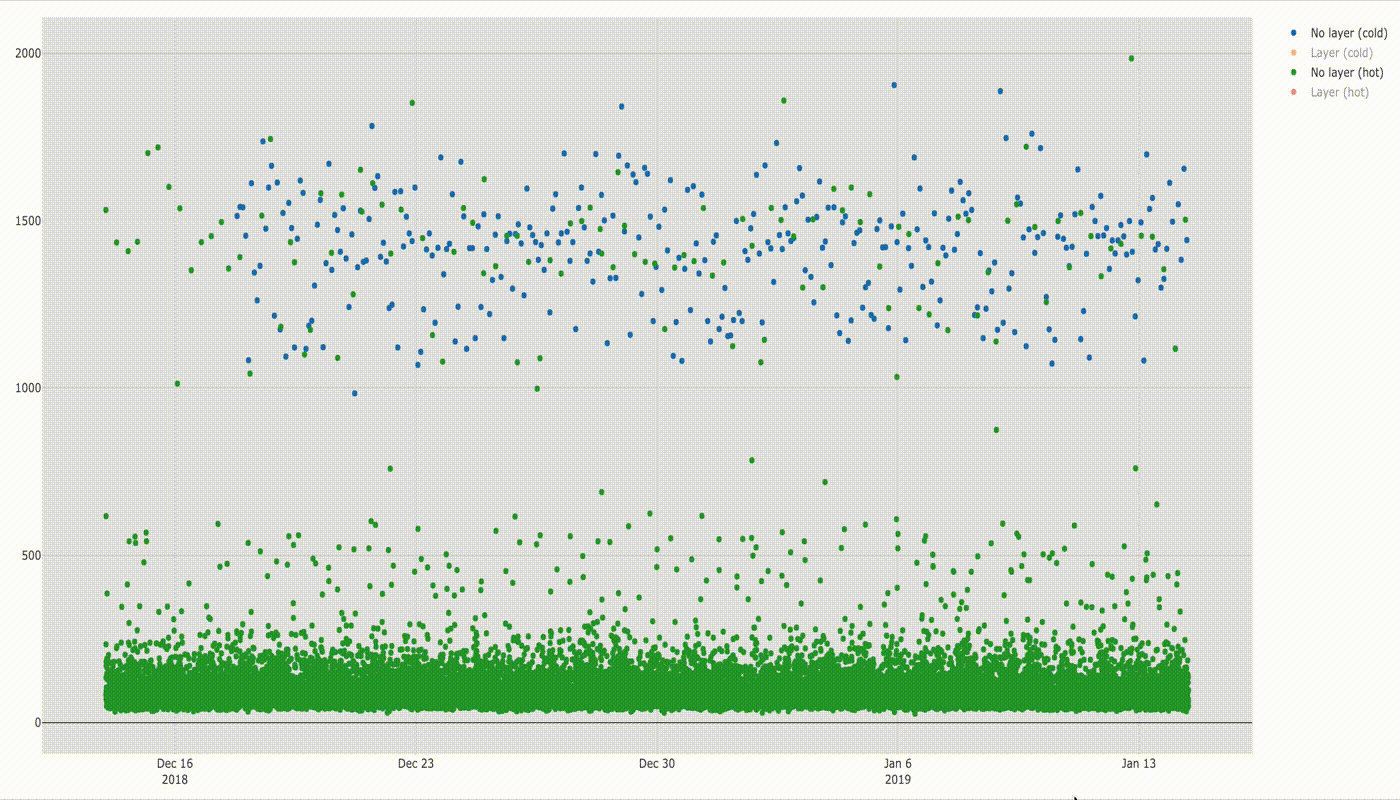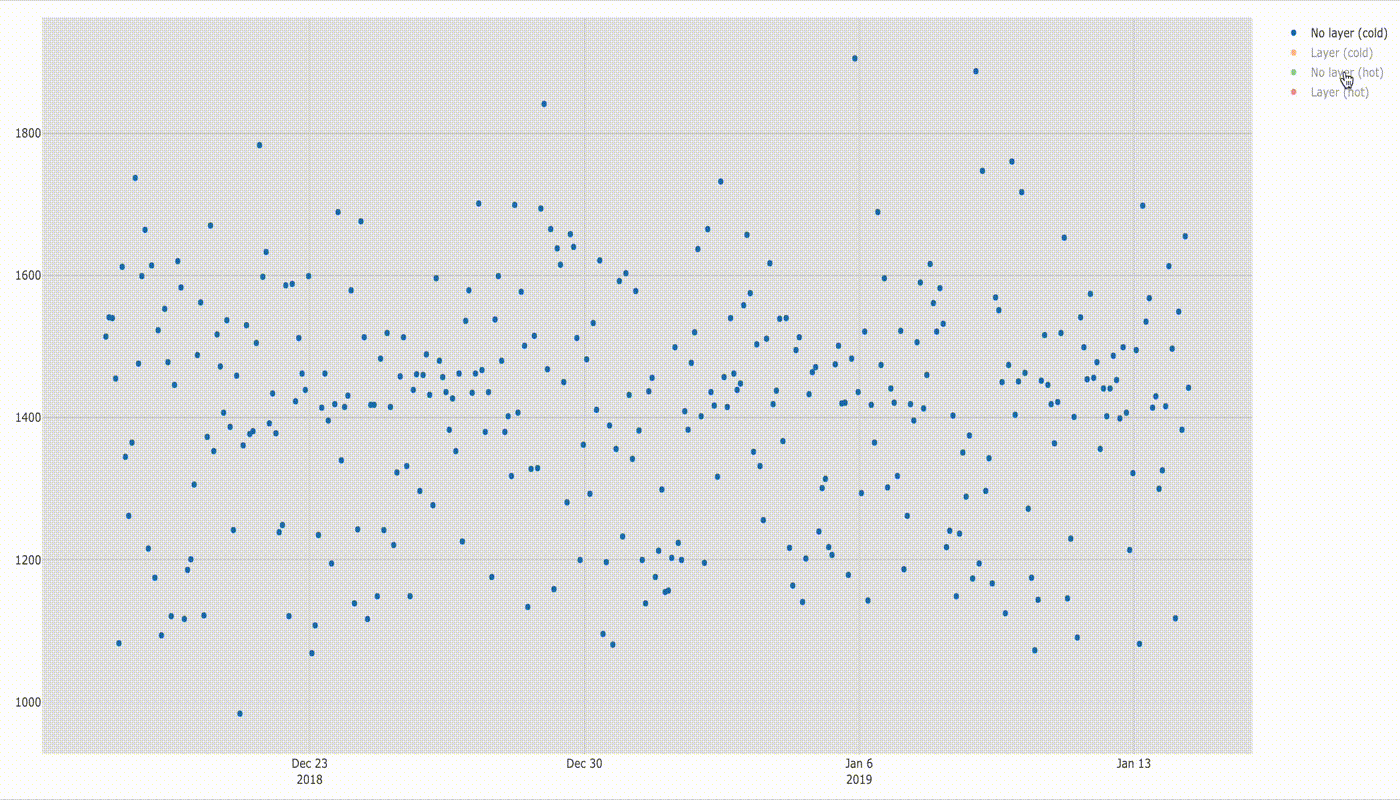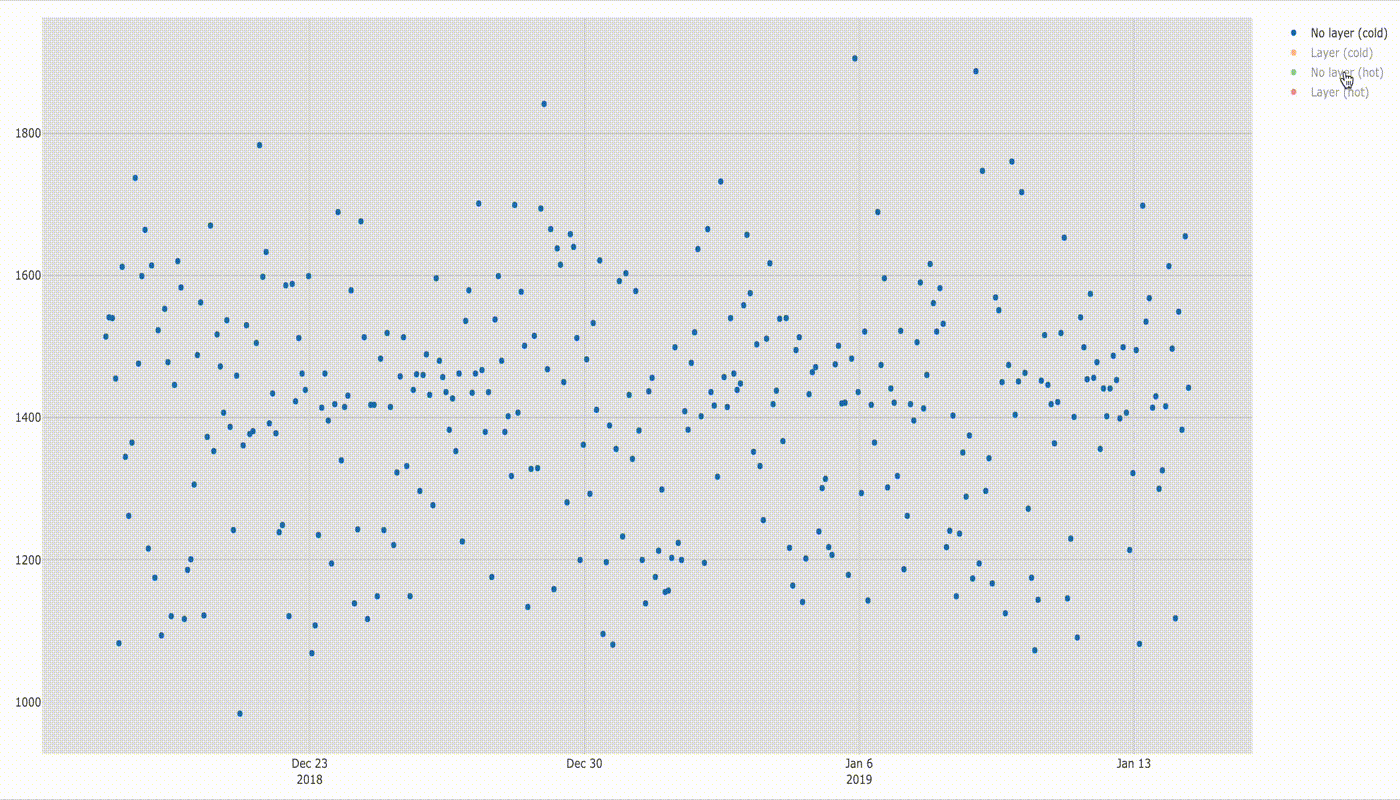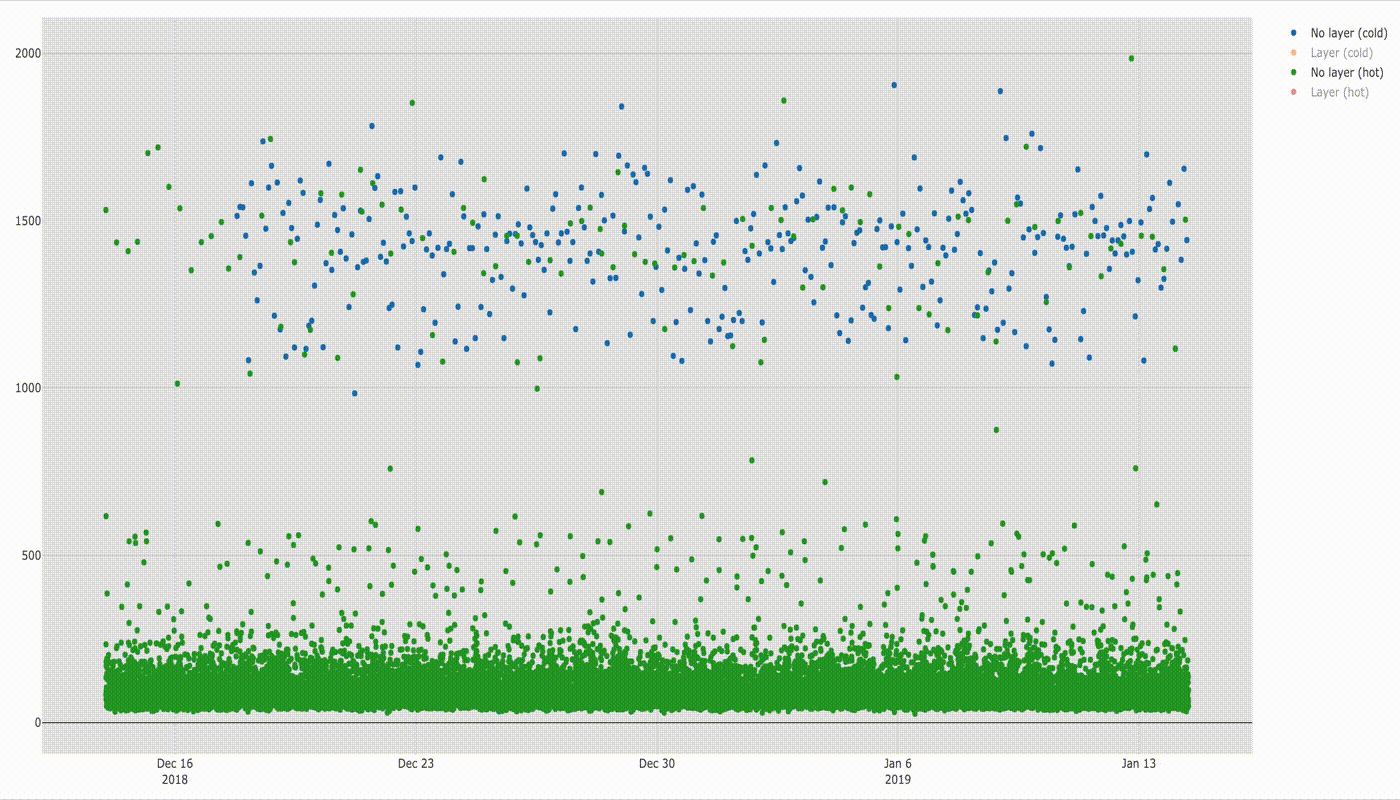
In this chart we can already see a huge difference in startup times for cold and hot lambdas. More can be seen when comparing distribution of samples on box diagram below.
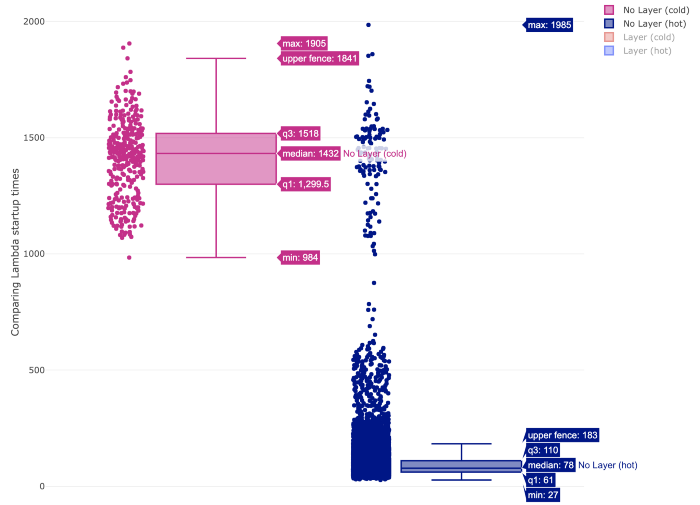
If you compare startup times of cold lambda and hot lambda the difference is amazing: cold lambda starts about 18 times slower than hot one ( e.g. compare medians:~1432ms/78ms =~18). Here you can also see what I already explained before, that some of hot lambda startup times lay in the ranges for cold lambda startup times (1–2 s) even though I triggered the function every 2 minutes.
Lambda cold and hot with layer
Similar situation when comparing execution times of cold and hot Lambda with layer — huge differences for cold and hot, but similar when user with or without layers.
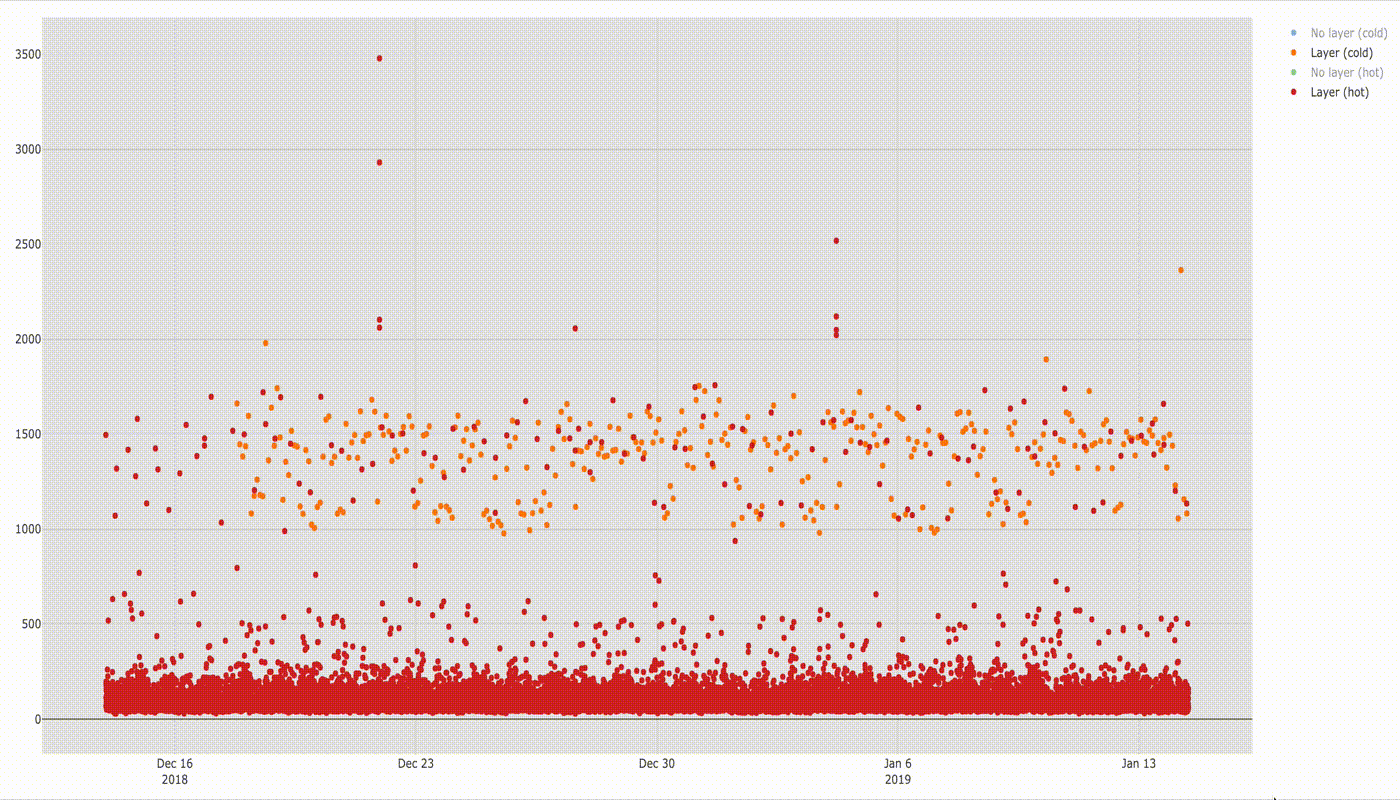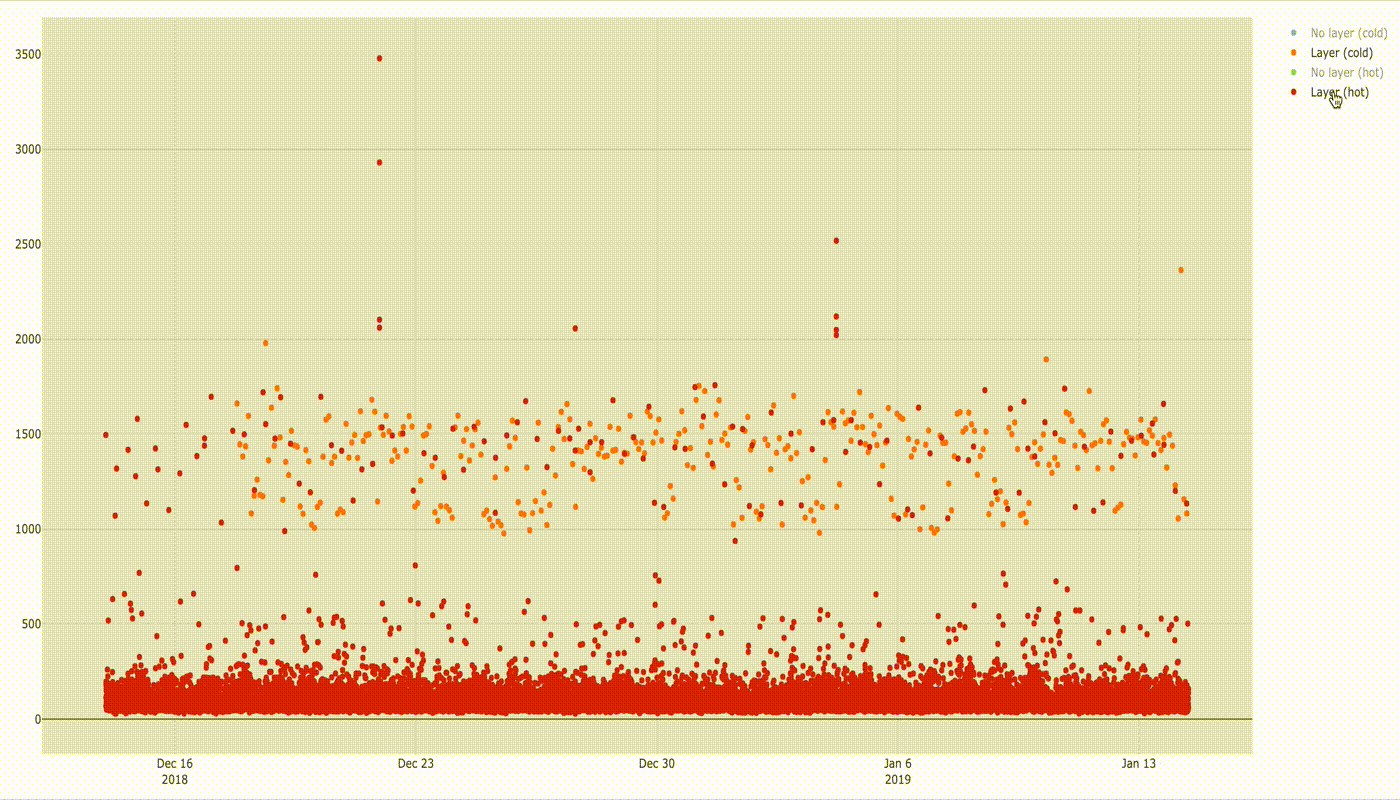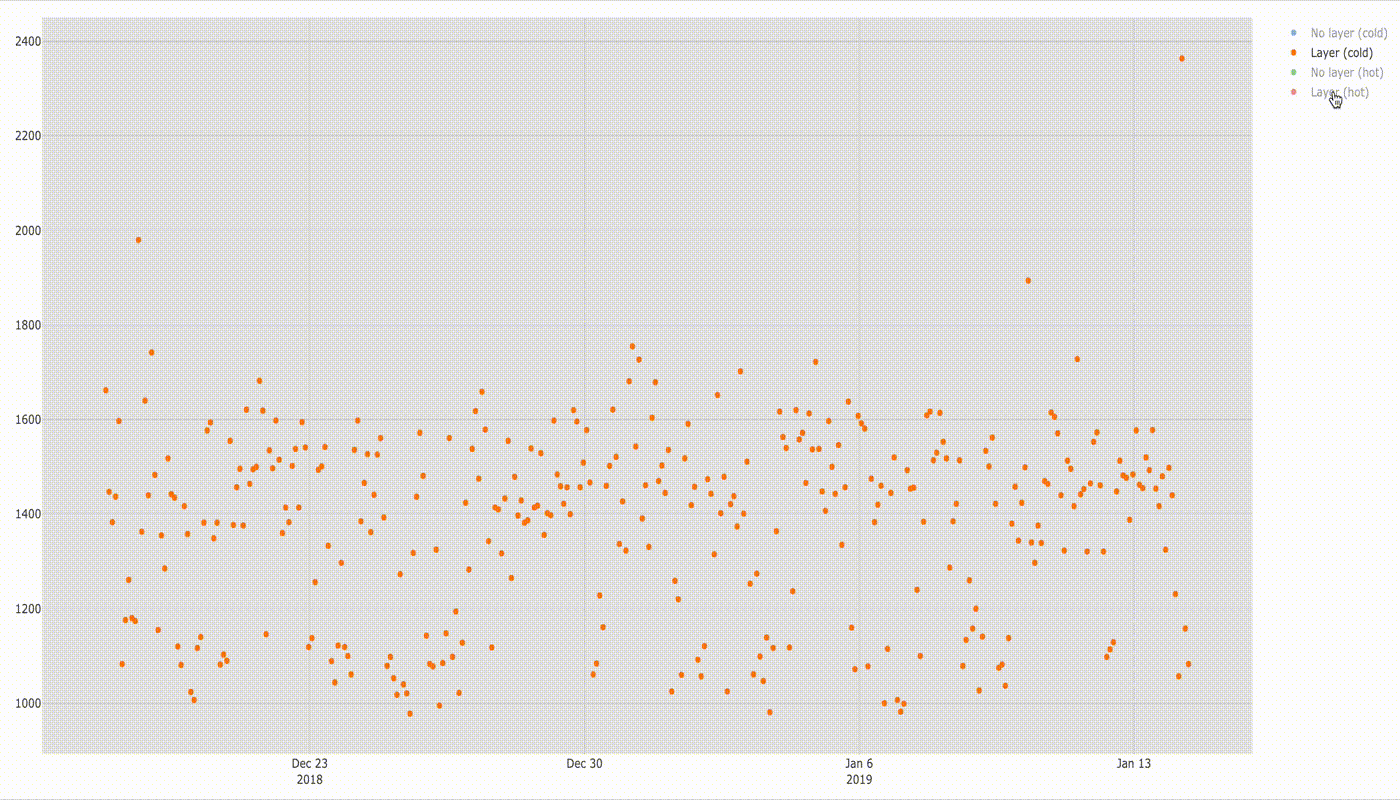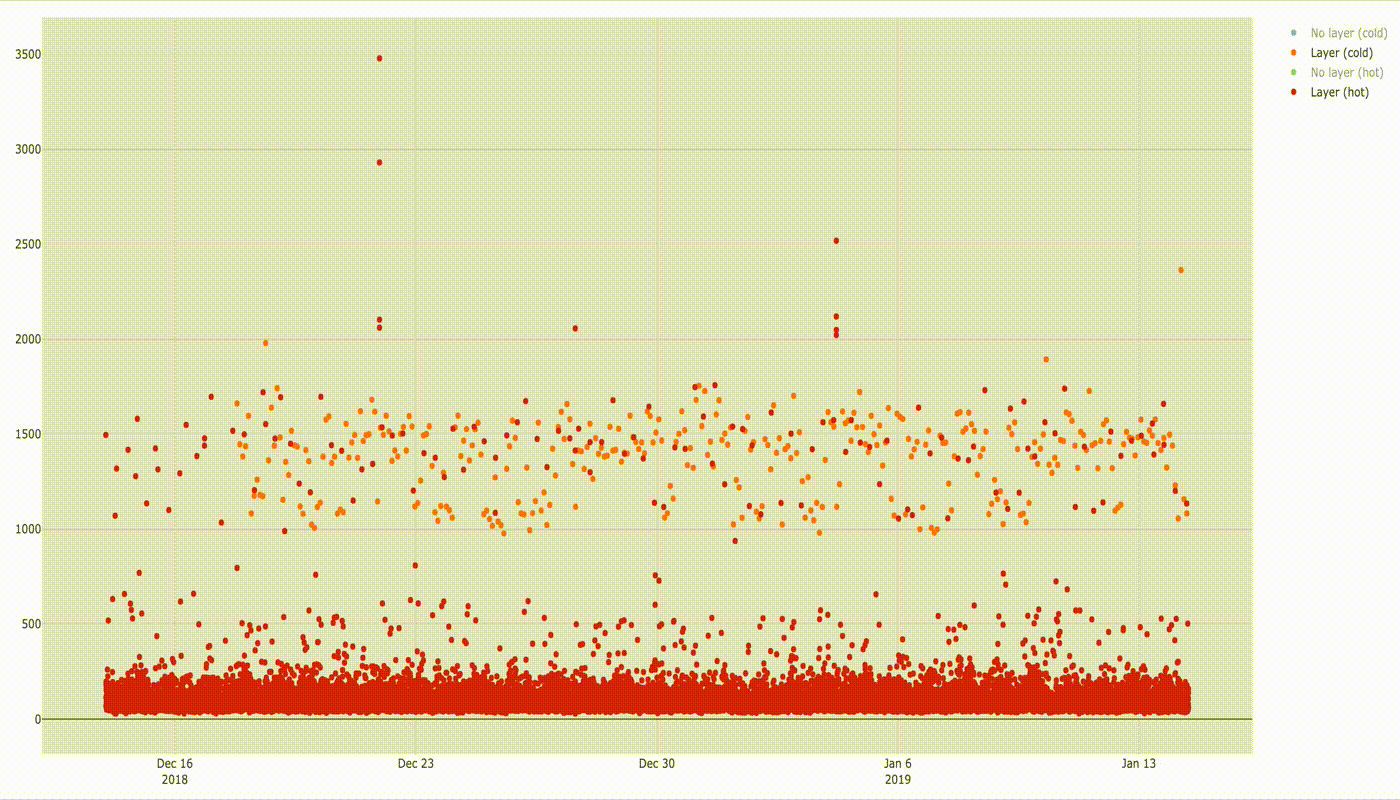
Summary
Just by chance of inspecting how layers impact Lambda execution time it came out that the quickest execution for cold Lambda was still about 32 times slower that the quickest for hot Lambda (e.g. with layers: ~978ms/29ms). There is also larger distribution of execution times for cold than for hot Lambda which means we can estimate execution time of hot lambda with better precision. Though sometimes it looks like even for hot lambda AWS destroys and image and a new one has to start.
I did not spot any significant difference of using the layer in Lambda function.
Probably the results also depends on the content of the layer, e.g. if any additional executables need to be installed, etc. In my case the layer contained only some static content (jar files in particular) and nothing had to be installed on it, but it would be interesting to measure the other case as well.
comments powered by Disqus